I get asked, fairly regularly, why Zeidman Development spent so many years focused almost exclusively on Raiser’s Edge. The honest answer is that Raiser’s Edge is hard, and we got good at it. After 25 years working in that ecosystem, we understood not just the product but the way non-profits actually use it – the quirks, the workarounds, the tribal knowledge that never makes it into any documentation. Building Importacular on that foundation made sense.
So why Salesforce now? And why Mailchimp integration specifically?
The answer, if I’m being direct about it, is that we kept seeing the same problem in a different context.
The Integration Gap Nobody Talks About
There are plenty of tools that will connect your CRM to Mailchimp. Most of them work, in the sense that data moves from one system to the other and nothing obviously catches fire. What they don’t do particularly well is handle the complexity of nonprofit data – and that complexity is, frankly, the whole point.
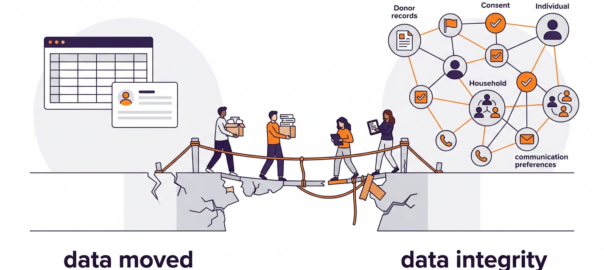
A standard connector treats your donors like marketing leads. It syncs a name, an email address, maybe a phone number, and calls that a success. What it doesn’t know about is your gift aid status, your constituent codes, your householding setup (where a couple shares a single record but each needs to receive different communications depending on their individual giving history), or your carefully defined opt-out preferences – the ones where a supporter has said yes to the newsletter but no to appeals, or yes to email but no to postal, and where getting that wrong isn’t just an inconvenience but a compliance risk.
This is what I’d call the integration gap: the space between “data moved” and “data integrity maintained.” Most tools live entirely on the first side of that gap and leave you to sort out the second.
The consequence of this – and I’ve seen it repeatedly – is what I think of as the human middleware problem. The admin who doesn’t quite trust the automation, so they export a CSV on Monday morning, clean it in Excel for a couple of hours, and import it manually. Every week. They’re not being irrational. They’ve just been burned enough times that they’ve lost faith in the sync. The automation is running, technically, but a person is doing the actual work anyway.
That’s not a solution. It’s just a more complicated version of the problem you started with.
Building for the 20%
When we started work on Chimpegration for Salesforce, the design principle I kept coming back to was this: most integrations work for 80% of the data. Nonprofits live in the other 20%.
The 20% is complex householding where a couple shares a record but each has a different communication history and different preferences. It’s opt-out requirements that vary not just by person but by campaign type, channel, and jurisdiction – and where a single wrong sync could mean sending an appeal to someone who explicitly asked not to receive one. It’s the edge cases that a generic tool simply hasn’t been designed to handle, because it was designed for a much simpler use case.
Getting the 80% right isn’t particularly difficult. There are plenty of tools that do it adequately. The interesting engineering problem – and the one we’ve spent a lot of time on – is making the 20% reliable.
Scalability is part of this too. A tool that works beautifully with 500 contacts and starts misbehaving at 50,000 isn’t actually solving the problem; it’s just deferring it. We needed Chimpegration to handle 5,000 donors as comfortably as 500,000. Two specific problems we designed around: API rate limits (both Mailchimp and Salesforce restrict how many requests a tool can make in a given time window, and a poorly designed sync will hit those limits mid-run, leaving you with some records updated and some not) and sync loops (where a change in Salesforce triggers an update in Mailchimp, which triggers an update back in Salesforce, which triggers Mailchimp again – and so on, potentially corrupting data across thousands of records before anyone notices).
The approach we landed on is granular user control over how data flows, rather than a black box that makes decisions on your behalf. I know that sounds obvious, but it’s actually a fairly deliberate choice that goes against a trend in integration tooling towards “just connect and it works.” The “just works” approach is fine until it doesn’t, and when it doesn’t, you have no visibility into why and no mechanism to fix it. We’d rather give you the controls upfront and document them clearly.
The Global Reality of Nonprofit Data
One thing that became apparent fairly quickly during development is that “worldwide tool” is not a simple promise to make.
We have customers in the UK, across the EU, in Canada, and in the United States, and the privacy obligations they operate under are not the same. GDPR is not PIPEDA. PIPEDA is not the patchwork of privacy laws across North America (which, frankly, I find more complicated to reason about than GDPR, but that’s a separate conversation). A tool that was built with only one regulatory context in mind will cause problems for organisations operating in others.
We built Chimpegration for Salesforce with privacy considerations from the start rather than bolting them on afterwards. I won’t pretend that compliance is exciting to write about, but it genuinely matters – particularly for organisations handling donor data across borders. If you’d like the specifics, our security documentation covers the implementation in more detail.
The Real Cost of “Free”
I want to say something about cost, because it comes up a lot.
There are free and very cheap integrations available. Some of them are perfectly adequate for small organisations with simple data. But the true cost of an integration isn’t the subscription price – it’s the total time your team spends managing it. Every hour an admin spends cleaning a CSV export is an hour not spent on fundraising, programme delivery, or supporter relations. That time has a real value, even if it doesn’t show up as a line item anywhere.
When your Salesforce instance and your Mailchimp account are genuinely in sync – properly in sync, with data you can trust – something useful happens: your marketing team can actually rely on their segments. A campaign targeted at major donors who’ve lapsed in the last 18 months reaches the right people. A welcome series for new supporters doesn’t accidentally include someone who asked to be removed from communications six months ago. These are not small things.
Data-driven fundraising is a phrase I’ve seen used to describe almost anything, but the basic premise is sound. You can’t make good decisions from bad data, and you can’t trust data that’s being manually reconciled once a week by someone who’s lost faith in the automation.
Why Now, and What’s Next
Chimpegration for Salesforce is now live. We’re not positioning it as an experiment or an early access product – it’s built on 15 years of experience developing integration tools for the nonprofit sector, and it reflects everything we’ve learned (including, let’s be honest, some of the things we got wrong early on with Chimpegration for Raiser’s Edge and corrected over time).
I said at the start that we moved into Salesforce because we kept seeing the same problem in a different context. The integration gap in the Salesforce/Mailchimp space is real, and the human middleware problem is just as prevalent there as anywhere else. We think we can help.
We didn’t build this to be first to market. We built it to be the last tool you’ll need for this particular task.
If you’re currently using a different integration and you’re nodding along to any of the problems I’ve described here, I’d be genuinely interested to hear about your experience. And if you’d like to see what Chimpegration for Salesforce can do for your organisation, you know where to find us.





